
Google Scholar |
X |
LinkedIn |
Hi! I'm a research scientist at Google DeepMind, working on multimodal AI for robotics. I'm specifically excited about video pre-training, utilizing human videos as a scalable data source, and exploring world models. I was previously at Optimus AI, Tesla, where I led projects for learning manipulation skills from ego-centric human video and sim2real RL for robust locomotion. I graduated with a PhD in Robotics from Carnegie Mellon University in 2024, advised by Prof. Deepak Pathak. Prior to that, I worked on reinforcement learning with Prof. Sergey Levine . You can contact me via email at rmendonca -at- google dot com |

|
webpage |
pdf |
abstract |
bibtex |
The current paradigm for motion planning generates solutions from scratch for every new problem, which consumes significant amounts of time and computational resources. For complex, cluttered scenes, motion planning approaches can often take minutes to produce a solution, while humans are able to accurately and safely reach any goal in seconds by leveraging their prior experience. We seek to do the same by applying data-driven learning at scale to the problem of motion planning. Our approach builds a large number of complex scenes in simulation, collects expert data from a motion planner, then distills it into a reactive generalist policy. We then combine this with lightweight optimization to obtain a safe path for real world deployment. We perform a thorough evaluation of our method on 64 motion planning tasks across four diverse environments with randomized poses, scenes and obstacles, in the real world, demonstrating an improvement of 23%, 17% and 79% motion planning success rate over state of the art sampling, optimization and learning based planning methods. |
|
webpage |
pdf |
abstract |
bibtex |
To build generalist robots capable of executing a wide array of tasks across diverse environments, robots must be endowed with the ability to engage directly with the real world to acquire and refine skills without extensive instrumentation or human supervision. This work presents a fully autonomous real-world reinforcement learning framework for mobile manipulation that can both independently gather data and refine policies through accumulated experience in the real world. It has several key components: 1) automated data collection strategies by guiding the exploration of the robot toward object interactions, 2) using goal cycles for world RL such that the robot changes goals once it has made sufficient progress, where the different goals serve as resets for one another, 3) efficient control by leveraging basic task knowledge present in behavior priors in conjunction with policy learning and 4) formulating generic rewards that combine human-interpretable semantic information with low-level, fine-grained state information. We demonstrate our approach on Boston Dynamics Spot robots in continually improving performance on a set of four challenging mobile manipulation tasks and show that this enables competent policy learning, obtaining an average success rate of 80% across tasks, a 3-4 times improvement over existing approaches. |
|

|
webpage |
abstract
We have made significant progress towards building foundational video diffusion models. As these models are trained using large-scale unsupervised data, it has become crucial to adapt these models to specific downstream tasks, such as video-text alignment or ethical video generation. Adapting these models via supervised fine-tuning requires collecting target datasets of videos, which is challenging and tedious. In this work, we instead utilize pre-trained reward models that are learned via preferences on top of powerful discriminative models. These models contain dense gradient information with respect to generated RGB pixels, which is critical to be able to learn efficiently in complex search spaces, such as videos. We show that our approach can enable alignment of video diffusion for aesthetic generations, similarity between text context and video, as well long horizon video generations that are 3X longer than the training sequence length. We show our approach can learn much more efficiently in terms of reward queries and compute than previous gradient-free approaches for video generation. |
|
webpage |
pdf |
abstract |
bibtex |
Deploying robots in open-ended unstructured environments such as homes has been a long-standing research problem. However, robots are often studied only in closed-off lab settings, and prior mobile manipulation work is restricted to pick-move-place, which is arguably just the tip of the iceberg in this area. In this paper, we introduce Open-World Mobile Manipulation System, a full-stack approach to tackle realistic articulated object operation, e.g. real-world doors, cabinets, drawers, and refrigerators in open-ended unstructured environments. The robot utilizes an adaptive learning framework to initially learns from a small set of data through behavior cloning, followed by learning from online practice on novel objects that fall outside the training distribution. We also develop a low-cost mobile manipulation hardware platform capable of safe and autonomous online adaptation in unstructured environments with a cost of around 20,000 USD. In our experiments we utilize 20 articulate objects across 4 buildings in the CMU campus. With less than an hour of online learning for each object, the system is able to increase success rate from 50% of BC pre-training to 95% using online adaptation. |
|
|
webpage |
pdf |
abstract |
bibtex |
Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train “generalist” X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. |
|
|
webpage |
pdf |
abstract |
bibtex |
We tackle the problem of learning complex, general behaviors directly in the real world. We propose an approach for robots to efficiently learn manipulation skills using only a handful of real-world interaction trajectories from many different settings. Inspired by the success of learning from large-scale datasets in the fields of computer vision and natural language, our belief is that in order to efficiently learn, a robot must be able to leverage internet-scale, human video data. Humans interact with the world in many interesting ways, which can allow a robot to not only build an understanding of useful actions and affordances but also how these actions affect the world for manipulation. Our approach builds a structured, human-centric action space grounded in visual affordances learned from human videos. Further, we train a world model on human videos and fine-tune on a small amount of robot interaction data without any task supervision. We show that this approach of affordance-space world models enables different robots to learn various manipulation skills in complex settings, in under 30 minutes of interaction. |
|
|
webpage |
pdf |
abstract |
bibtex |
Building a robot that can understand and learn to interact by watching humans has inspired several vision problems. However, despite some successful results on static datasets, it remains unclear how current models can be used on a robot directly. In this paper, we aim to bridge this gap by leveraging videos of human interactions in an environment centric manner. Utilizing internet videos of human behavior, we train a visual affordance model that estimates where and how in the scene a human is likely to interact. The structure of these behavioral affordances directly enables the robot to perform many complex tasks. We show how to seamlessly integrate our affordance model with four robot learning paradigms including offline imitation learning, exploration, goal-conditioned learning, and action parameterization for reinforcement learning. We show the efficacy of our approach, which we call Vision-Robotics Bridge (VRB) as we aim to seamlessly integrate computer vision techniques with robotic manipulation, across 4 real world environments, over 10 different tasks, and 2 robotic platforms operating in the wild. |
|
|
webpage |
pdf |
abstract |
bibtex |
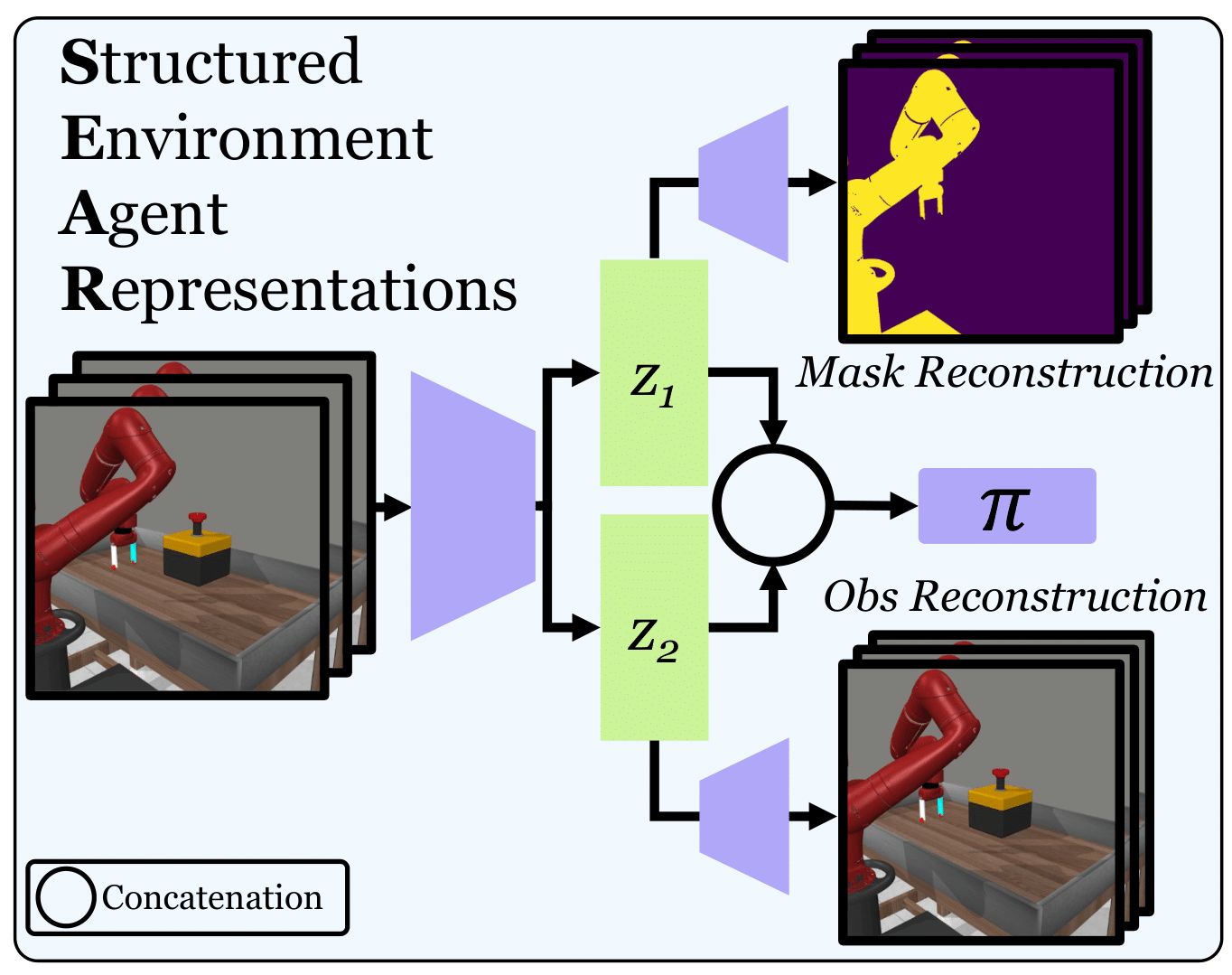
Agents that are aware of the separation between the environments and themselves can leverage this understanding to form effective representations of visual input. We propose an approach for learning such structured representations for RL algorithms, using visual knowledge of the agent, which is often inexpensive to obtain, such as its shape or mask. This is incorporated into the RL objective using a simple auxiliary loss. We show that our method, SEAR (Structured Environment-Agent Representations), outperforms state-of-the-art model-free approaches over 18 different challenging visual simulation environments spanning 5 different robots. |
|
webpage |
pdf |
abstract |
bibtex |
Robotic agents that operate autonomously in the real world need to continuously explore their environment and learn from the data collected, with minimal human supervision. While it is possible to build agents that can learn in such a manner without supervision, current methods struggle to scale to the real world. Thus, we propose ALAN, an autonomously exploring robotic agent, that can perform many tasks in the real world with little training and interaction time. This is enabled by measuring environment change, which reflects object movement and ignores changes in the robot position. We use this metric directly as an environment-centric signal, and also maximize the uncertainty of predicted environment change, which provides agent-centric exploration signal. We evaluate our approach on two different real-world play kitchen settings, enabling a robot to efficiently explore and discover manipulation skills, and perform tasks specified via goal images. |
|

|
webpage |
pdf |
abstract |
bibtex |
code |
benchmark |
talk video
How can artificial agents learn to solve wide ranges of tasks in complex visual environments in the absence of external supervision? We decompose this question into two problems, global exploration of the environment and learning to reliably reach situations found during exploration. We introduce the Latent Explorer Achiever (LEXA), a unified solution to these by learning a world model from the high-dimensional image inputs and using it to train an explorer and an achiever policy from imagined trajectories. Unlike prior methods that explore by reaching previously visited states, the explorer plans to discover unseen surprising states through foresight, which are then used as diverse targets for the achiever. After the unsupervised phase, LEXA solves tasks specified as goal images zero-shot without any additional learning. We introduce a challenging benchmark spanning across four standard robotic manipulation and locomotion domains with a total of over 40 test tasks. LEXA substantially outperforms previous approaches to unsupervised goal reaching, achieving goals that require interacting with multiple objects in sequence. Finally, to demonstrate the scalability and generality of LEXA, we train a single general agent across four distinct environments.
@inproceedings{mendonca2021lexa,
Author = {Mendonca, Russell and
Rybkin, Oleh and Daniilidis, Kostas and
Hafner, Danijar and Pathak, Deepak},
Title = {Discovering and Achieving
Goals via World Models},
Booktitle = {NeurIPS},
Year = {2021}
}
|
|
webpage |
pdf |
abstract |
bibtex |
code |
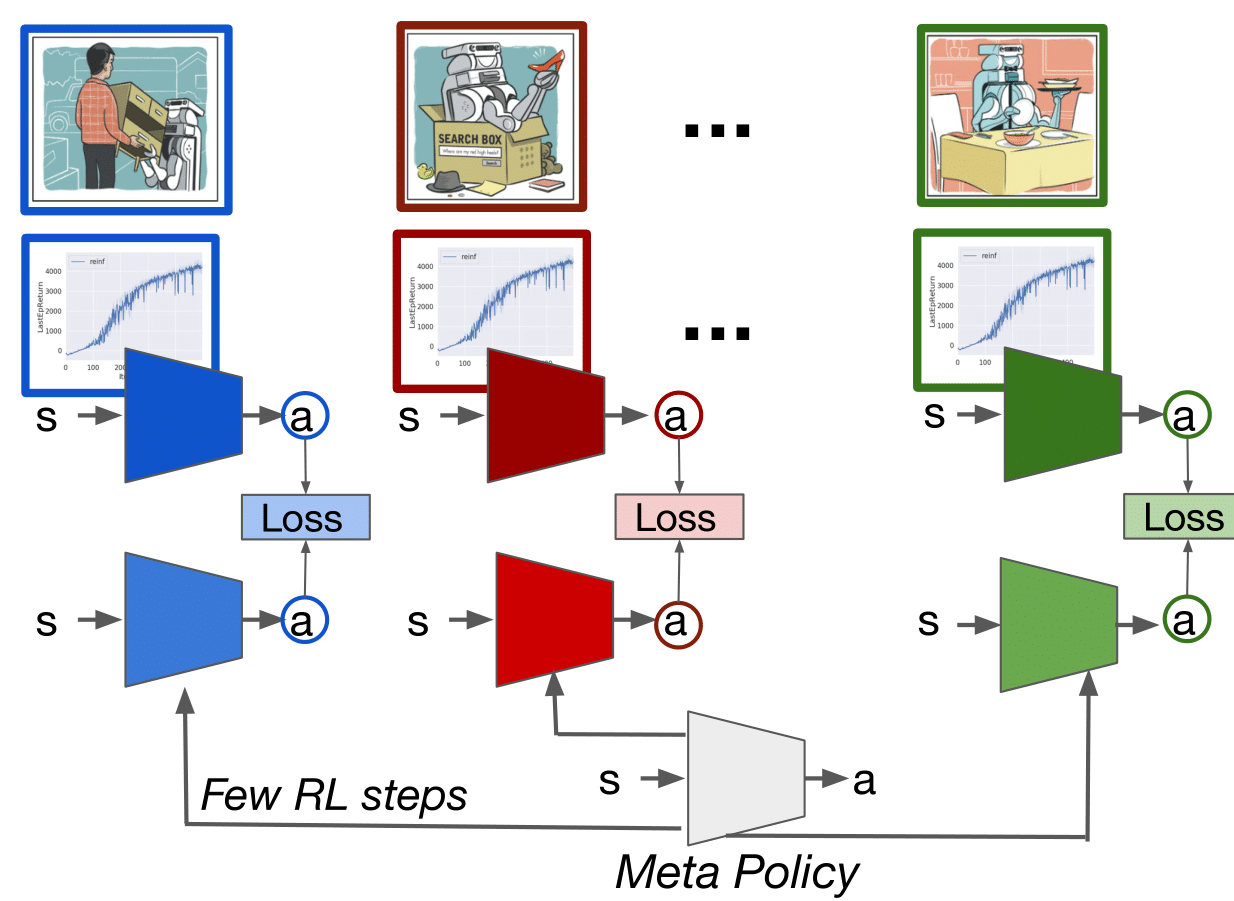
We develop an algorithm which can meta-learn in a data efficient manner and also train on raw visual input, by reformulating the meta-learning objective to have imitation learning as a subroutine. We show about an order of magnitude sample efficiency gain on challenging simulation environments, and much more stable learning from high dimensional image observations as compared to prior state of the art methods.
@inproceedings{mendonca2019gmps,
Author = {Mendonca, Russell and
Gupta, Abhishek and Kralev, Rosen and
Abbeel, Pieter and Levine,
Sergey and Finn, Chelsea},
Title = {Guided Meta-Policy Search},
Booktitle = {NeurIPS},
Year = {2019}
}
|
|
slides |
pdf |
abstract |
bibtex |
code |
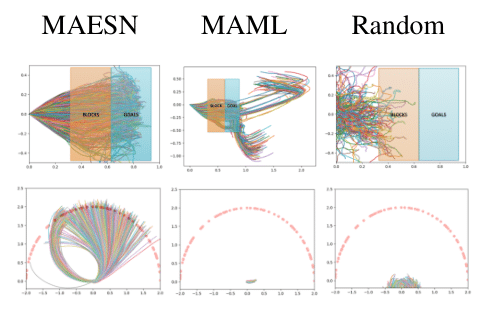
We design a meta-learning algorithm that acquires coherent exploration strategies, in addition to adapting quickly to new tasks. This enables learning on new tasks with sparse feedback. Given a set of tasks, we meta-learn a representation space and then explore in the learnt task space instead of the space of random actions, resulting in more meaningful exploratory behavior.
@inproceedings{gupta2018maesn,
Author = {Gupta, Abhishek and
Mendonca, Russell and Liu, YuXuan and
Abbeel, Pieter and Levine, Sergey},
Title = {Meta-Reinforcement Learning
of Structured Exploration Strategies},
Booktitle = {NeurIPS},
Year = {2018}
}
|
|
pdf |
abstract |
bibtex |
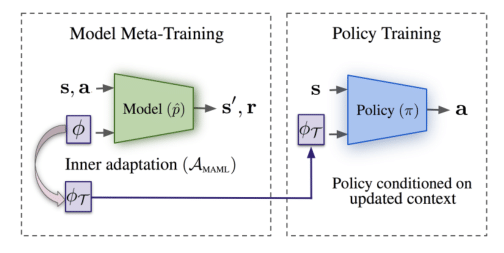
We develop a meta-learning algorithm that can generalize efficiently to unfamiliar tasks. Recognizing that supervised learning is much more effective than RL for extrapolation to out-of-distribution tasks, we meta-learn models of state dynamics, for which a natural supervised objective exists. Given a new task, we use synthetic data generated from the learned model for continued training, ensuring that extrapolation is highly data-efficient.
@misc{mendonca2020metareinforcement,
title={Meta-Reinforcement Learning
Robust to Distributional Shift
via Model Identification
and Experience Relabeling},
author={Russell Mendonca and Xinyang
Geng and Chelsea Finn and Sergey Levine},
year={2020},
eprint={2006.07178},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
|
Modified version of template from here |